Broken Machine Windows - Debugging a custom TensorFlow.js DCGAN model
| Philipp GrossA story of debugging and fixing a DCGAN model, trained with PyTorch, and deployed with Tensorflow.js, that gives inconsistent results in different browser platforms.
During our collaboration with machine learning researcher Claartje Barkhof Machine Windows we trained a GAN on a custom dataset of colored shapes following the PyTorch DCGAN tutorial and converted the generator network to a TensorFlow.js model for deployment in the browser.
As the generator network is compute intense we didn't execute it on the main thread but ran a service worker instead.
For example by sampling 16 random points from the 100-dimensional input space and passing them through the generator gives 16 images:
 4x4 grid of generated images using the WebGL backend
4x4 grid of generated images using the WebGL backend
In this example, I use Chrome as the browser, but when running the same experiment in Safari on a different machine things turned messy:
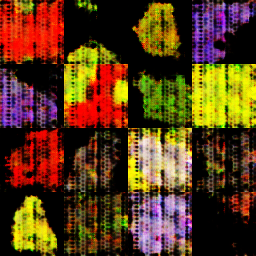 4x4 grid of generated images using the CPU backend
4x4 grid of generated images using the CPU backend
What changed? Consulting the documentation reveals that TensorFlow.js offloads the computation to a global backend that is determined by the environment. Here, Chrome uses the WebGL backend, but for some reason this didn't work in Safari but got silently replaced with the slower CPU backend.
It was disturbing. I can't be the first one stumbling over this.
Since TensorFlow.js is widely used and I basically just used the standard layers I must be doing something wrong. By dabbling with backend configuration, I was able to recreate the "bug" in Chrome by just executing
await tf.setBackend('cpu');Ok, at least we can rule out hardware specific quirks. Something must be going on with the CPU backend. Probably, I am one of the few noobs trying to run a GAN on the CPU. Of course I tried hard and begged TensorFlow to just accept the WebGL backend but gave up. Much later I learned that it is currently just not supported in Safari when running a service worker, only on the main thread. Premature optimization strikes again. Yikes.
Anyway, why look the results so different when using the CPU backend?
Let's dismantle the neural network and check when things start to fall apart. After all the network is just a sequence of layers:
| Layer | Type | Output Shape |
|---|---|---|
| 26 | Conv2DTranspose | 1,512,4,4 |
| 27 | BatchNormalization | 1,512,4,4 |
| 28 | Activation | 1,512,4,4 |
| 29 | Conv2DTranspose | 1,256,10,10 |
| 29_crop | Cropping2D | 1,256,8,8 |
| 30 | BatchNormalization | 1,256,8,8 |
| 31 | Activation | 1,256,8,8 |
| 32 | Conv2DTranspose | 1,128,18,18 |
| 32_crop | Cropping2D | 1,128,16,16 |
| 33 | BatchNormalization | 1,128,16,16 |
| 34 | Activation | 1,128,16,16 |
| 35 | Conv2DTranspose | 1,64,34,34 |
| 35_crop | Cropping2D | 1,64,32,32 |
| 36 | BatchNormalization | 1,64,32,32 |
| 37 | Activation | 1,64,32,32 |
| 38 | Conv2DTranspose | 1,3,66,66 |
| 38_crop | Cropping2D | 1,3,64,64 |
| image_batch | Activation | 1,3,64,64 |
So by looping through the layers and visualizing the intermediate outputs we can hope to find the culprit.
We start with the 100-dimensional input vector represented as a grayscale image of size:
const z = tf.randomNormal([1, 100, 1, 1]);
Now we pass it manually through the layers:
let temp = z;
// ommit the input layer
for (let i = 1; i < model.getConfig().layers.length; i++) {
const layer = model.getLayer(null, i);
temp = layer.apply(temp);
renderOutput(temp);
}
const result = temp;The following shows the intermediate outputs for both the WebGL and CPU backend:
| layer | WebGL | CPU |
|---|---|---|
| 26 |  |  |
| 27 |  |  |
| 28 |  |  |
| 29 |  |  |
| 29_crop |  |  |
| 30 |  |  |
| 31 |  |  |
| 32 |  |  |
| 32_crop |  |  |
| 33 |  |  |
| 34 |  |  |
| 35 |  |  |
| 35_crop |  |  |
| 36 |  |  |
| 37 | 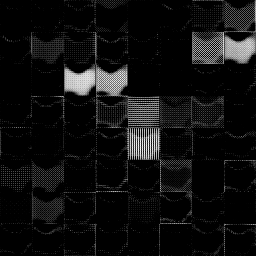 |  |
| 38 |  |  |
| 38_crop |  |  |
| image_batch |  |  |
Clearly, in layer 30 we see the first difference. This is a Batch Normalization layer, and a bit of internet search shows that we are on the right track: There is the issue Batchnormalization is incorrect with cpu backend and channelsFirst data. #1106. But it was automatically closed due to lack of interest (ha). Apparently, the majority of TFJS users either uses the WebGL backend, or works with channelsLast data, which is TensorFlow's default configuration. But we converted our model from PyTorch, where channelsFirst is the standard.
Since we didn't have the time to change the model and retrain it, we decided to fix the channel data format on the fly and do the batch normalization manually:
let temp = z;
// ommit the input layer
for (let i = 1; i < model.getConfig().layers.length; i++) {
const layer = model.getLayer(null, i);
if (layer.getClassName() === 'BatchNormalization') {
const [gamma, beta, movingMean, movingVar] = layer.weights.map(w =>
w.read(),
);
// to channels last
const x = temp.transpose([0, 2, 3, 1]);
// run batchNorm4d on channels last data format
const y = tf.batchNorm4d(
x,
movingMean,
movingVar,
beta,
gamma,
layer.epsilon,
);
// and convert back to channels first
temp = y.transpose([0, 3, 1, 2]);
} else {
temp = layer.apply(temp);
}
renderOutput(temp);
}
const result = temp;And it worked!
While this allows us to use the image generator network with the CPU backend it turned out that it is way to slow for our application. In the end we decided to run it on the main thread where the WebGL backend is available for all platforms, and just live with the consequences of having a blocked UI once in a while.