Findings on Pre-trained LayoutLM Language Model
| Nico LutzHere at Bakken & Bæck, prototyping is a huge part of getting an initial product to our clients. This blog posts highlights some findings that we came upon while creating a language model that involved training for multiple languages. Using pre-trained models is the butter to the bread in each machine learning prototype, especially in applications that are language model centric. The catch in this case is that the only pre-trained models that exist are in English and our use case involved mainly documents in Norwegian.
A client requires us to find information on a huge number of pdfs. Pdfs are always a bit cheesy to work with, sometimes they can have all the information you want in one place and a simple heuristic can get you all the information you need. But sometimes pdfs are just scanned documents that even the newest OCR tools have trouble reading from. Luckily, the pdfs we had from our client are perfectly machine readable and the text could be, easily extracted. The information we intend to get always lies on a similar location on the document. Naturally taking that position into account when extracting textual information comes to mind. Fortunately, Huggingface's great transformers library implements a series of transformer models that take layout information, in addition to the textual information, into account. Here we are focusing on a simple model called LayoutLM.
How LayoutLM works
Let's dive in by shortly explaining how the model works by citing the documentation:
The LayoutLM model was proposed in LayoutLM: Pre-training of Text and Layout for Document Image Understanding by Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. It’s a simple but effective pre-training method of text and layout for document image understanding and information extraction tasks, such as form understanding and receipt understanding.Also the schematics of the model architecture can illustrate the functionality more clearly.
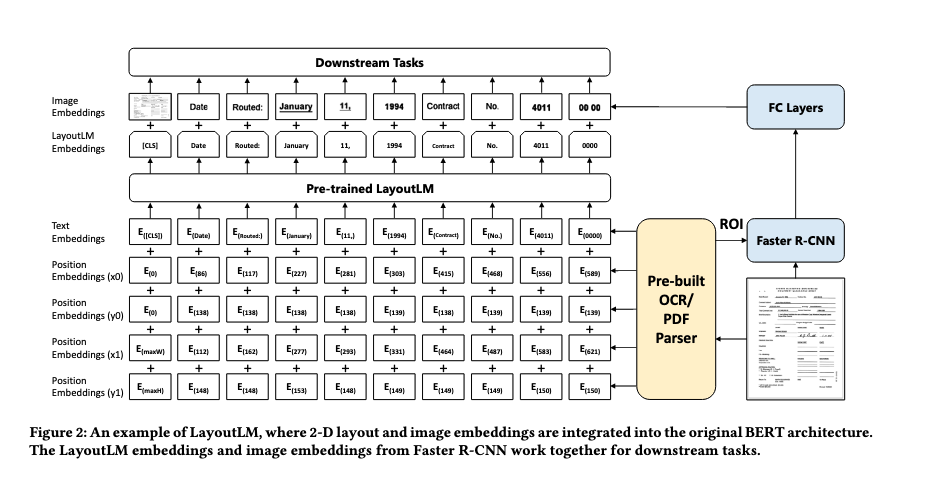 schema
of layoutlm, taken from arxiv.org
schema
of layoutlm, taken from arxiv.org
Basically, LayoutLM is a transformer based architecture with all the usual transformer components and (dis)advantages, such as fixed input vector, multi head capability and easy training. As you can see on the schema what differentiates this model from other transformer based models is its capability to take, in addition to the textual embeddings, 4(!) positional embeddings as input into account (x and y coordinates, width and height). This makes it a perfect fit for doing things amongst others like OCR Text Extraction or Receipt Understanding.
Training with different setups
As stated above our documents are mainly in Norwegian and since all the pre-trained models for LayoutLM are in English, we were faced with a choice of either picking another language model or trying our luck with using English as a baseline. The reasoning is that, linguistically speaking, Norwegian is not that far away from English and holds some similarities such as sentence structure, while (of course) being totally different on vocabulary. Nonetheless, it is instructive to try and see how different training setups perform under these circumstances. Prototyping with huggingface is so fast and easy that all the following different setups only take a minimal amount of time to test on. We tried using the following parameters:
- Using the pre-trained "English" tokenizer and the English pre-trained model, in addition to our Norwegian dataset for training (orange).
- Making a new tokenizer trained on Norwegian and still using the English pre-trained model and then training with our Norwegian dataset. Technically this is a totally dumb setup, since the English model is trained with a different tokenizer and there should be no corresponding semantics whatsoever (red).
- The new Norwegian tokenizer and LayoutLM from scratch with a small Norwegian dataset (blue).
- The new Norwegian tokenizer and LayoutLM from scratch with our normal Norwegian dataset (grey).
Below is a screenshot of different learning curves (accuracy, loss and precision on eval set) each representing one of the above setups:
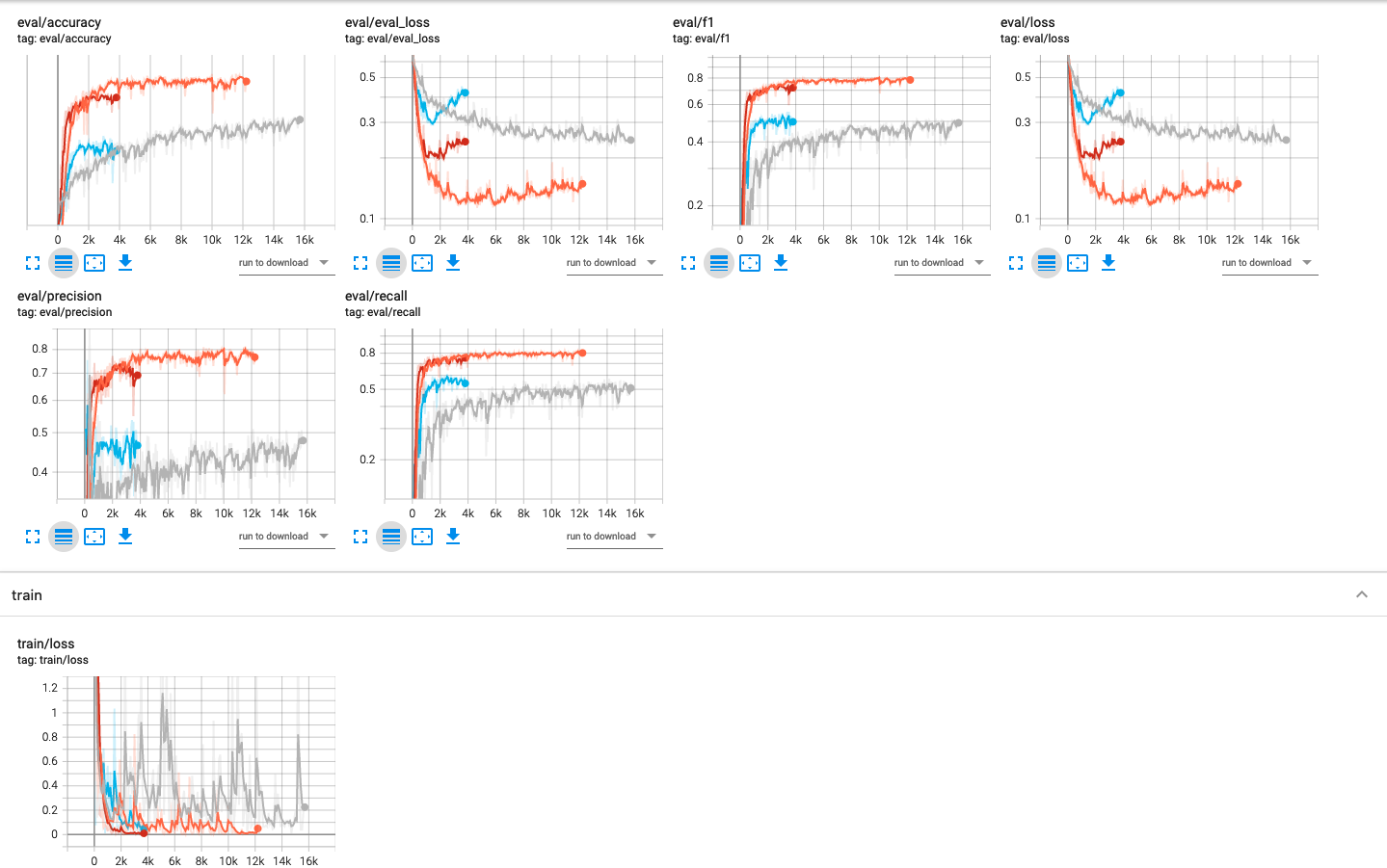 training LayoutLM under different initial setups
training LayoutLM under different initial setups
All in all one can see that accuracy drops when moving from the pre-trained model(red and orange) to the models trained from scratch(blue and grey). Even the setup by hijacking the english models weights with a new tokenizer(red) performed better than models learned from scratch. While it is not surprising to see that pre-trained models perform better than models trained from scratch, we were surprised to see that much of a margin. The explanation we came up with is that the usual explanations for language models doesn't hold for LayoutLM. As one can see on the schematics the model takes as input 5 input vectors that are then internally averaged, so looking at the distribution of textual vs positional embeddings it makes sense that 4/5 of the input is actual positionally focused and therefore the input distribution is skewed in favor of positional learnings. In conclusion a strong pre-trained model is more tuned towards positions instead of textual vectors.
While all we found is technically nothing new and shouldn't surprise the elaborated data scientist, it's still nice to actually see how models perform under (un)certain circumstances.